
Résolution de CAPTCHA en Data Scraping
Data Scraping & Résolution de Captcha : Le Guide Technique Complet
Extraire des données web à grande échelle sans se faire bloquer — de la configuration de votre bot jusqu'à la résolution de captchas forcés.
Qu'est-ce que le Data Scraping et à quoi ça sert ?
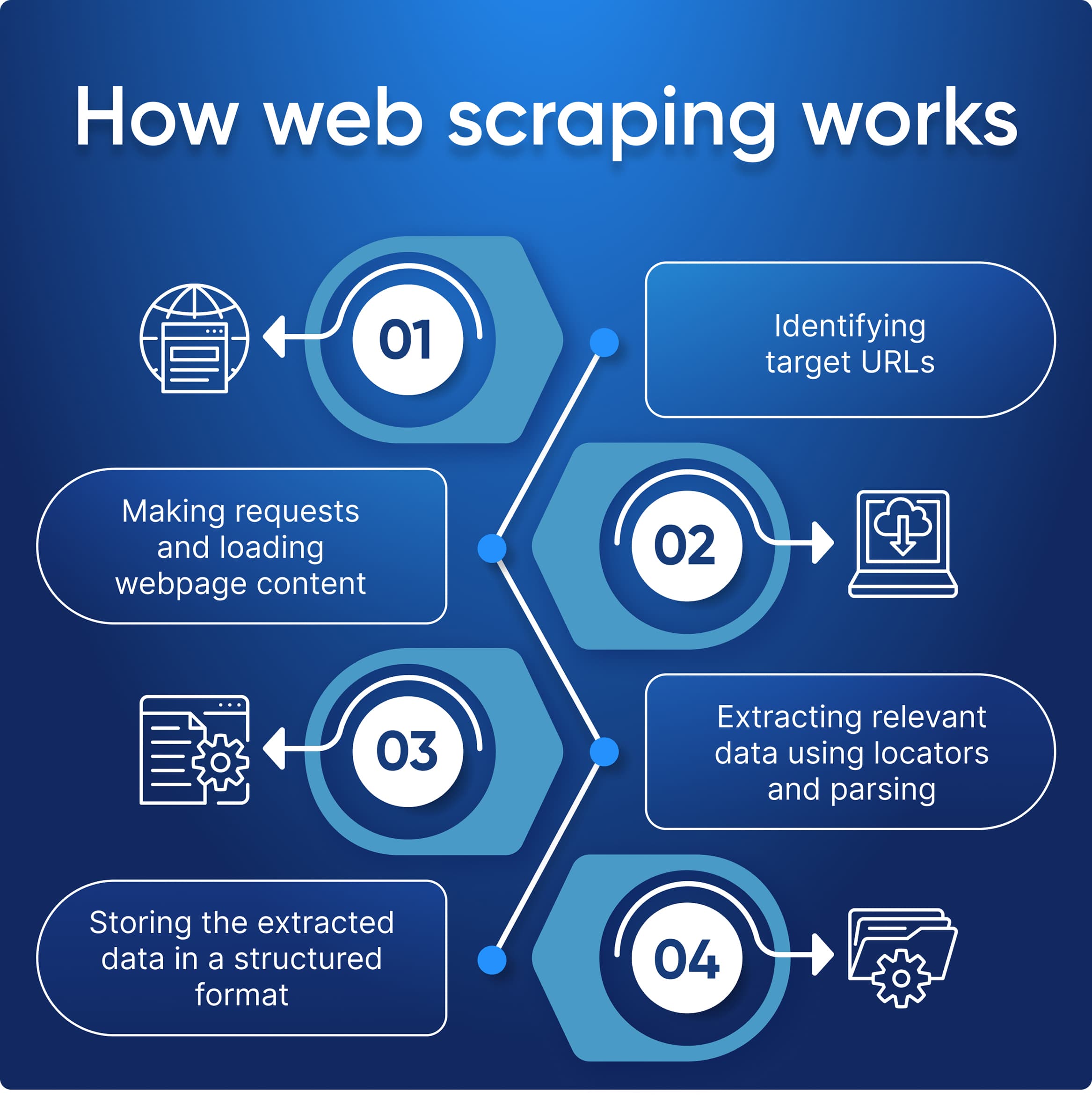
Le data scraping (ou web scraping) consiste à extraire automatiquement des données ciblées depuis des sites web — que ce soit quelques dizaines de lignes ou plusieurs millions d'entrées. Concrètement, on parle d'extraire des prix, des descriptions produits, des avis clients, des contacts, des articles, ou tout autre contenu accessible via un navigateur.
Les cas d'usage sont extrêmement variés :
- Marketing & veille concurrentielle : surveiller les prix de vos concurrents en temps réel, analyser leur catalogue produit
- Boost SEO : récupérer des données SERP, analyser les backlinks, monitorer des positions de mots-clés
- Automatisation de flux de données : alimenter automatiquement des Google Sheets, des CRMs, des dashboards
- Génération de leads : collecter des informations de contact depuis des annuaires professionnels
- Recherche et data science : constituer des datasets d'entraînement pour des modèles ML
Pour mettre en place un scraper, les deux outils de référence sont Selenium (Python/Java) et Puppeteer (Node.js). Les deux pilotent un vrai navigateur Chromium ou Firefox en arrière-plan — ils sont globalement interchangeables si vous ne rencontrez pas de captchas. Le choix dépend surtout de votre stack technique.
Le Vrai Défi : Passer Sous les Radars
La plupart des sites protègent leurs données contre les bots. Mais voici ce que beaucoup ignorent : nombreux sont ceux qui n'activent leurs protections captcha que lorsqu'un comportement robotique est détecté. En d'autres termes, un bot qui se comporte comme un humain ne déclenchera tout simplement pas la protection.
L'objectif est donc d'être le plus humanoïde possible. Voici les techniques essentielles :
1. Les Proxies Rotatifs
Un proxy rotatif est un service qui assigne une nouvelle adresse IP à chaque requête (ou à intervalles réguliers). Cela évite qu'une seule IP soit identifiée comme source d'un volume suspect de connexions et blacklistée. En utilisant des pools de centaines ou milliers d'IPs résidentielles, votre trafic ressemble à celui de multiples utilisateurs humains distincts.
2. Selenium Stealth / Puppeteer Stealth
Par défaut, un navigateur piloté par Selenium ou Puppeteer laisse des traces détectables dans les en-têtes JavaScript (navigator.webdriver = true, absence de plugins, etc.). Les plugins selenium-stealth et puppeteer-stealth patchent ces propriétés pour rendre le navigateur indiscernable d'un navigateur humain classique.
3. La Rotation des Headers HTTP
Les navigateurs envoient un ensemble de headers HTTP à chaque requête (User-Agent, Accept-Language, Referer...). Un bot qui envoie toujours les mêmes headers est facilement identifiable. Il faut varier ces headers à chaque session, en utilisant des User-Agents réalistes et cohérents avec le reste du profil.
4. Les Délais Aléatoires
Un humain ne clique pas à la milliseconde près. L'ajout de délais aléatoires entre les actions (scroll, clic, navigation) est une technique simple mais très efficace. Évitez les délais fixes (time.sleep(2)) : préférez des valeurs aléatoires dans une plage réaliste (random.uniform(1.5, 4.2)).
5. Simuler le Comportement Humain
Au-delà des délais, on peut aller plus loin : simuler des mouvements de souris aléatoires, un scroll progressif, des pauses de lecture, ou même des faux retours en arrière dans l'historique de navigation.
Vérifier son Setup sur bot.sannysoft.com
Avant de lancer votre scraper en production, il existe un outil incontournable : bot.sannysoft.com. Ce site effectue une batterie de tests sur votre navigateur et vous indique précisément quelles protections seraient activées contre vous. Chaque test est accompagné d'un résultat vert (non détecté) ou rouge (détecté comme bot). C'est le meilleur moyen de valider votre configuration avant de commencer.
Quand le Captcha Est Inévitable : Les 2 Options
Malgré toutes ces précautions, certains sites imposent un captcha systématique, indépendamment du comportement du bot. Il faut alors le résoudre. Deux approches s'offrent à vous.
Option 1 — Les APIs de Résolution (ex. Bright Data)
La solution la plus simple : déléguer. Des services comme Bright Data, 2Captcha, ou Anti-Captcha exposent des APIs qui prennent en charge la résolution de captchas (reCAPTCHA v2/v3, hCaptcha, Cloudflare Turnstile...). Vous envoyez le captcha, ils vous retournent le token de validation.
Avantages : intégration rapide, fiable, aucune maintenance.
Inconvénients : coût variable selon le volume. À petite échelle (quelques centaines de résolutions par jour), c'est tout à fait abordable. Pour du scraping massif et continu, la facture peut grimper significativement et doit être anticipée dans le ROI du projet.
Option 2 — La Résolution Manuelle / Semi-automatique
Pour ceux qui veulent maîtriser toute la chaîne, une approche DIY est possible :
- Screenshot automatique du captcha via le navigateur headless
- Envoi vers un modèle de vision (GPT-4o, Claude, Gemini) ou un logiciel OCR tiers (Tesseract, Google Vision API) pour interprétation
- Récupération et injection du résultat dans le formulaire
Cette méthode fonctionne bien pour les captchas textuels ou les puzzles simples. Pour les reCAPTCHA v3 (qui analysent le comportement global de la session), elle est insuffisante seule et doit être combinée avec les techniques d'humanisation décrites plus haut.
Une autre approche complémentaire : les services de résolution humaine en temps réel (crowdsourcing), où de vraies personnes résolvent les captchas à la demande via une API — 2Captcha utilise ce modèle hybride.
Récapitulatif : La Stack Recommandée
| Besoin | Outil recommandé |
|---|---|
| Pilotage du navigateur | Selenium (Python) ou Puppeteer (Node.js) |
| Anti-détection navigateur | selenium-stealth / puppeteer-stealth |
| Rotation d'IPs | Proxies rotatifs résidentiels |
| Validation du setup | bot.sannysoft.com |
| Résolution captcha (simple) | Bright Data / 2Captcha API |
| Résolution captcha (DIY) | Screenshot + Vision API (OCR) |
Conclusion
Le data scraping est un outil puissant, mais son efficacité repose à 80% sur la qualité du setup anti-détection plutôt que sur le scraper lui-même. En combinant proxies rotatifs, stealth plugins, headers dynamiques et délais humanoïdes, vous passerez sous les radars de la grande majorité des protections. Pour les cas où le captcha est inévitable, les APIs dédiées restent la solution la plus rapide à déployer, tandis que l'approche OCR/IA offre une alternative économique pour les volumes importants.
Rappel légal : assurez-vous toujours que le scraping que vous réalisez est conforme aux CGU du site cible et aux réglementations en vigueur (RGPD notamment pour les données personnelles).


